はじめに:JSONって、そのままSnowflakeに入れていいの? WebサービスのAPIログ、IoTのセンサーデータ、SaaSからエクスポートしたデータ……現代のデータって、行と列がきれいに並んだ表ばかりじゃないですよね。むしろ
JSON形式 のような「ネストした構造」のデータを扱うことが増えています。
「これって、いったん整形してからじゃないとデータベースに入らないんじゃ……?」と思った方、ご安心を!Snowflakeには
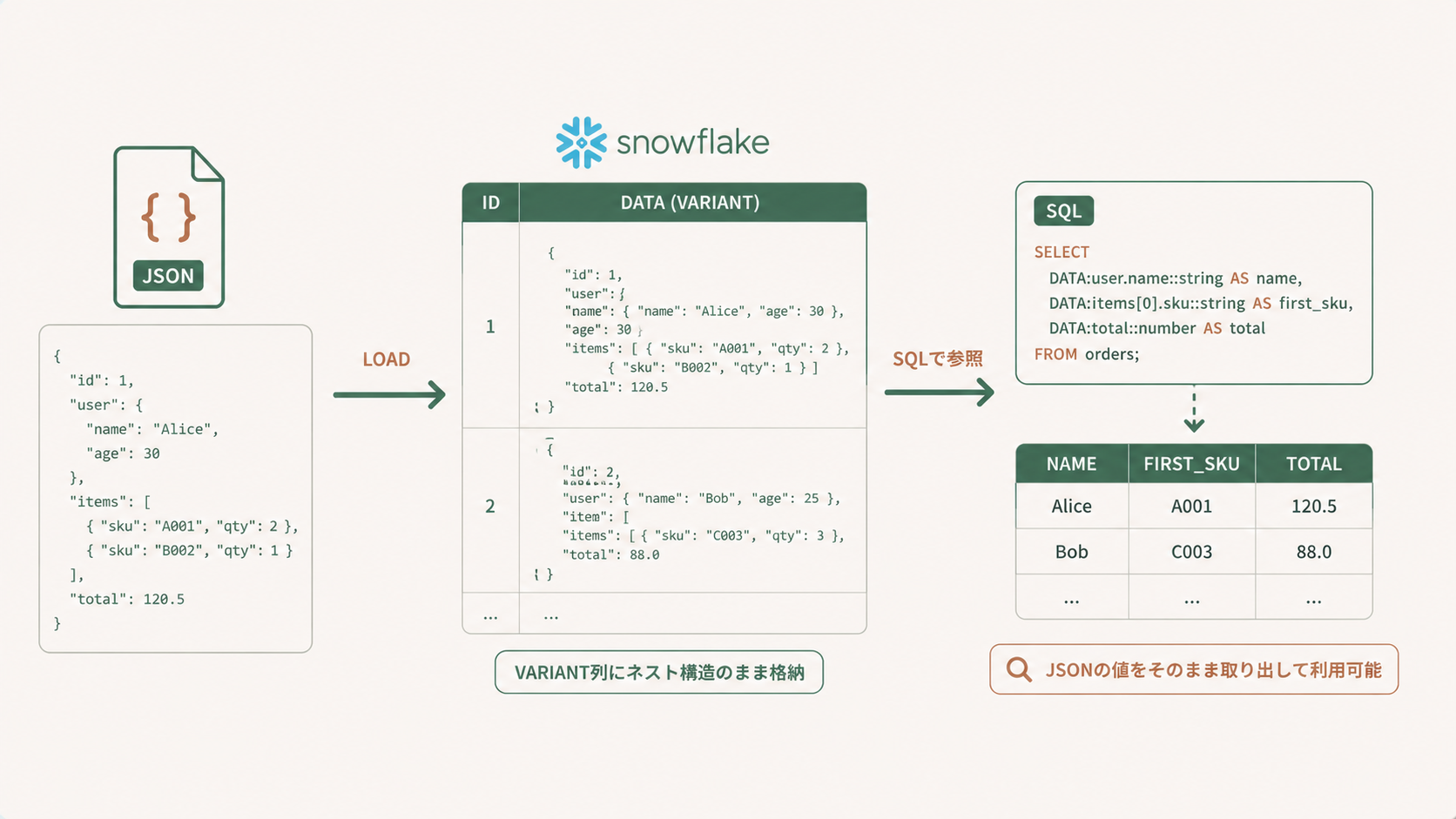
VARIANT型 という魔法のようなデータ型があり、
JSONをそのままの形でテーブルに突っ込める んです。この記事では、VARIANT型の基本と、JSONをロードして値を取り出す方法を、初心者向けにやさしく解説します。
半構造化データとVARIANT型の基本 半構造化データとは? 半構造化データ とは、行と列でガチガチに決まった「構造化データ」と、まったく形のない「非構造化データ」の中間にあるデータのこと。代表例が
JSON ・XML・Avro・Parquetなどです。「キーと値のペア」を持っていて意味は読み取れるけれど、データごとに項目がバラバラだったりネストしていたりします。
Snowflakeが扱える形式の全体像は、過去記事の
「Snowflake対応ファイル形式まとめ|CSV/JSON/Parquet/Avroの違い」 でも紹介しています。
VARIANT型ってどんな型? VARIANT型 は、Snowflake独自の「なんでも入る箱」のようなデータ型です。文字列・数値・配列・オブジェクトなど、JSONで表現できるあらゆる構造をそのまま保持できます。最大サイズは1行あたり16MB(圧縮後)。スキーマを事前に決めなくていいので、API仕様が変わっても柔軟に取り込めるのが大きな魅力です。
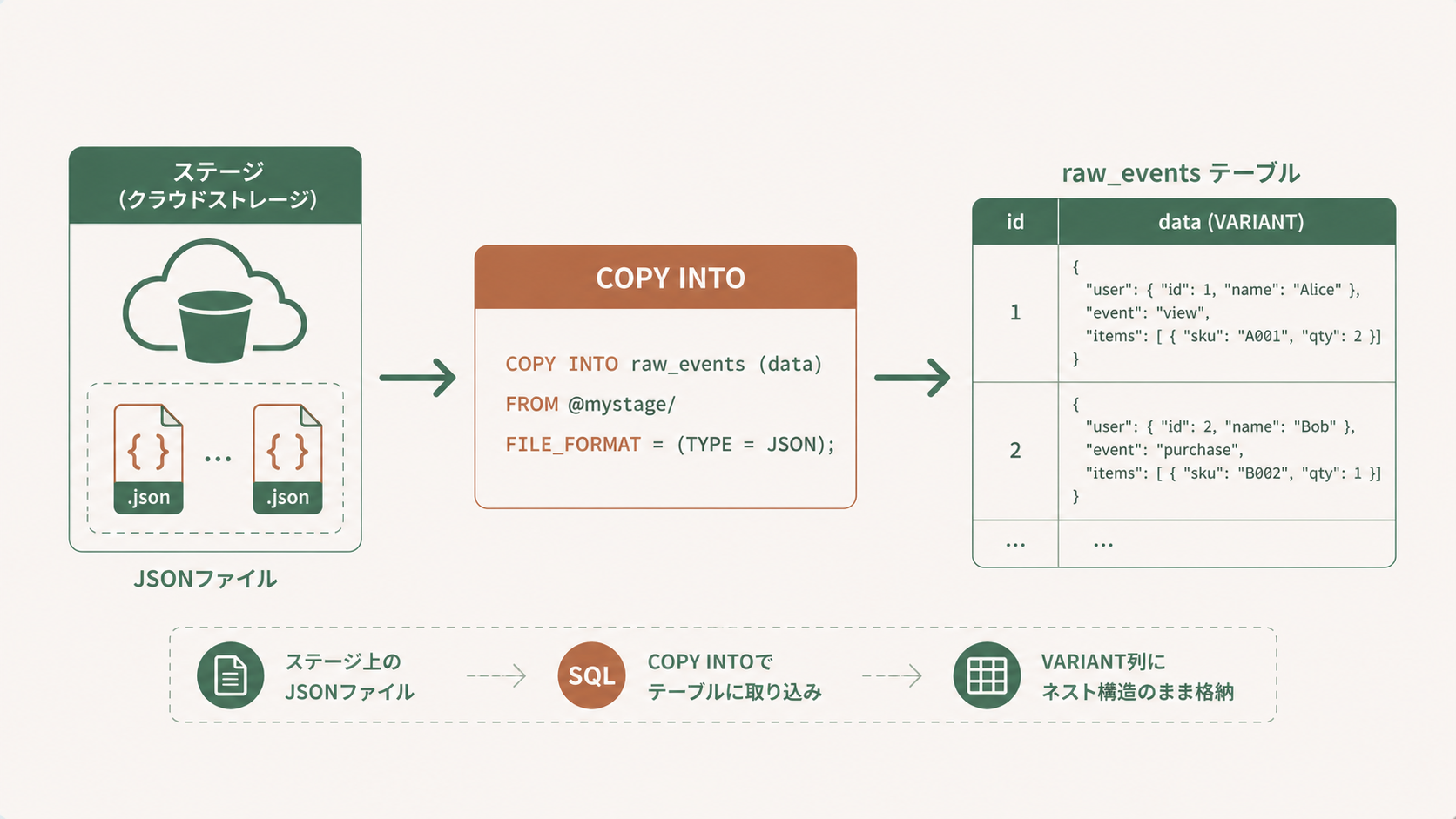
JSONをロードしてみよう ステップ1:VARIANT列を持つテーブルを作る まずは VARIANT 型のカラムを1つだけ持つテーブルを用意します。
CREATE OR REPLACE TABLE raw_events (
payload VARIANT
);ステップ2:JSON用のファイルフォーマットを定義 JSONを読み込むためのフォーマットオブジェクトを作成します。詳しい作り方は
「Snowflakeファイルフォーマットの作り方と使い方をやさしく解説」 を参照してください。
CREATE OR REPLACE FILE FORMAT my_json_format
TYPE = JSON
STRIP_OUTER_ARRAY = TRUE;STRIP_OUTER_ARRAY = TRUE は「ファイル全体が配列で囲まれている場合に、その外側のカッコを外して1要素ずつ行にする」便利オプションです。
ステップ3:ステージからCOPY INTOでロード 事前に
ステージ にJSONファイルを置いたら、
COPY INTO で取り込むだけです。
COPY INTO raw_events
FROM @my_stage/events.json
FILE_FORMAT = (FORMAT_NAME = my_json_format);VARIANTから値を取り出す 例えば次のようなJSONが入っているとします。
{
"user": { "id": 101, "name": "Hanako" },
"items": [
{ "sku": "A001", "qty": 2 },
{ "sku": "B002", "qty": 1 }
]
}
VARIANT列の中身は
ドット記法 や
角括弧 でスルッとアクセスできます。
SELECT
payload:user.id::NUMBER AS user_id,
payload:user.name::STRING AS user_name,
payload:items[0].sku::STRING AS first_sku
FROM raw_events;
末尾の
::NUMBER や
::STRING は型変換(キャスト)です。VARIANTのまま扱うと文字列として表示されてしまうので、明示的にキャストするのがコツ。
配列を行に展開する FLATTEN 配列を1行ずつバラしたいときは
FLATTEN 関数の出番です。
SELECT
payload:user.id::NUMBER AS user_id,
f.value:sku::STRING AS sku,
f.value:qty::NUMBER AS qty
FROM raw_events,
LATERAL FLATTEN(input => payload:items) f;
これでアイテムごとに1行ずつ取り出せ、通常のテーブルのように集計やJOINができます。
使いどころと注意点
得意なシーン : APIレスポンス、アプリのイベントログ、IoTセンサーデータなど、項目が増減する可能性のあるデータ。注意点 : VARIANTのままだとクエリのたびにパースが入るため、頻繁に使う列は ビュー や 計算列 として固定スキーマに展開すると性能・可読性ともに向上します。1行あたり 16MB の上限を超えないようにファイル分割しておくと安心。
まとめ Snowflakeの
VARIANT型 を使えば、JSONを「いったんCSVに変換して……」なんて面倒な前処理をしなくても、生のままロードしてSQLで自由に扱えます。CSVと同じく
COPY INTO で取り込み、ドット記法や
FLATTEN で値を取り出すだけ。半構造化データの扱いに苦手意識のあった方も、ぜひ手を動かして体感してみてください!
参考リンク 関連記事 この記事を書いた人 Soma
現役のデータエンジニア(6年目)。Snowflakeをはじめとするデータ基盤技術と、セイバーメトリクス・国内外の旅行記をゆるく書いています。
プロフィール詳細