
はじめに:なぜ「ファイル形式」を知る必要があるの?
Snowflakeにデータを取り込むとき、最初に立ちはだかる壁が「そのファイル、どんな形式?」という問題です。CSV・JSON・Parquet・Avro・ORC・XML……名前は聞いたことがあるけど違いがピンとこない、という方も多いのではないでしょうか。 ファイル形式によって ロード速度・容量・分析性能・スキーマ管理のしやすさ が大きく変わります。「とりあえずCSV」と決めてしまうと、本番運用に乗ってからストレージコストやクエリ性能で後悔することも珍しくありません。 この記事では、Snowflakeがサポートする主要ファイル形式を 比較表 で俯瞰し、それぞれの特徴・向き不向き・選び方・実際のFILE FORMAT オブジェクトの作成例まで、初心者にもやさしくまとめます。

サポートされるファイル形式の全体像
Snowflakeでロード(COPY INTO)とアンロードできる代表的な形式は次のとおりです。
- 構造化データ: CSV(=区切り文字つきテキスト)
- 半構造化データ: JSON / Avro / ORC / Parquet / XML
- 非構造化データ: 画像・PDFなど(ステージで保管し、Snowparkや関数で処理)
ファイル形式の比較表
Snowflakeで使われる主要6形式を一気に俯瞰できる比較表です。| 形式 | 分類 | 行/列指向 | スキーマ | 圧縮効率 | 分析性能 | 主な用途 |
|---|---|---|---|---|---|---|
| CSV | 構造化 | 行指向 | なし | △ 低い | △ 低い | 手作業エクスポート / 小規模データ / 人が中身を確認したい場合 |
| JSON | 半構造化 | 行指向(テキスト) | 柔軟(ネストOK) | △ 低い | ○ 中(VARIANT) | APIレスポンス / Webログ / NoSQLからの取り込み |
| Parquet | 半構造化 | 列指向(バイナリ) | あり(ファイル内) | ◎ 高い | ◎ 高い | データレイク / 大規模分析 / 外部テーブル |
| Avro | 半構造化 | 行指向(バイナリ) | あり + 進化に強い | ○ 中 | ○ 中 | Kafkaなどストリーミング / スキーマ頻繁更新 |
| ORC | 半構造化 | 列指向(バイナリ) | あり(ファイル内) | ◎ 高い | ○ 高い | Hive資産の移行 / Hadoopエコシステム連携 |
| XML | 半構造化 | 行指向(テキスト) | DTD/XSDで定義可 | △ 低い | △ 中 | レガシー連携 / 金融や行政の標準フォーマット |
※「分析性能」はSnowflakeでの列単位読み取り・プルーニング・統計情報の効きやすさを総合した目安です。実測値はデータ量や圧縮設定で変わります。
形式別の特徴と向き不向き
① CSV:いちばん身近なテキスト形式
カンマ区切りでおなじみのCSV。Excelやどんなツールでも開けるのが最大の強みです。一方で 型情報を持たない・圧縮効率が低い ため、大量データには不向き。区切り文字や改行コード・引用符の扱いでハマりがちなのも要注意ポイントです。- 向いている: 小規模なマスタ投入 / Excel経由のデータ受け渡し / 人がそのまま中身を確認したい場合
- 向いていない: TB級のデータ / 列ごとの選択読み取りが多い分析ワークロード
- 注意: エンコーディング(UTF-8 / Shift-JIS)・区切り文字・引用符・
NULLの表現をFILE FORMATで必ず明示する
② JSON:Webやログとの相性ばつぐん
APIレスポンスやアプリログでよく使われるJSON。ネストした構造をそのまま保持できる のが魅力で、SnowflakeではVARIANT 型に丸ごと格納してSQLで掘り下げられます。半面、テキストベースなのでサイズは大きくなりがちです。
- 向いている: APIレスポンスのそのままロード / ネスト構造のまま分析したい
- 向いていない: 列単位での集計が多いシンプルなテーブル(その場合はParquetへ変換)
- Tips: 1行=1レコードの JSON Lines (NDJSON) 形式が扱いやすい
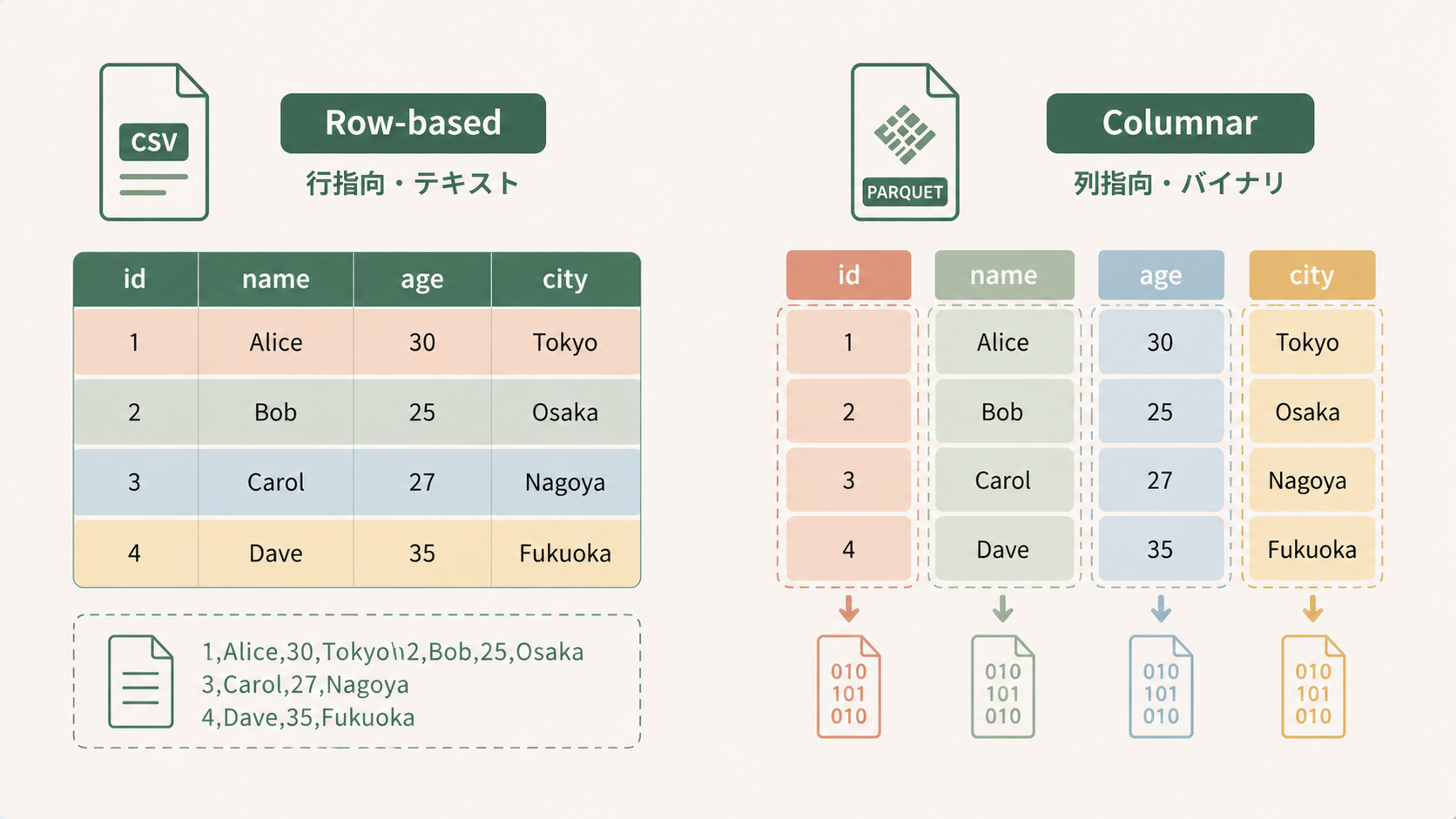
③ Parquet:分析にいちばん強い列指向フォーマット
列ごとにまとめて格納する 列指向(カラムナ) 形式で、必要な列だけを高速に読めるのが特徴。圧縮効率も高く、ビッグデータ分析の事実上の標準 と言える存在です。Snowflakeのマイクロパーティション設計とも親和性が高く、外部テーブルでも本領を発揮します。- 向いている: データレイク / 大規模分析 / S3などへの外部テーブル接続
- 向いていない: 1行ずつ追記する用途(行指向のAvroのほうが効率的)
- Tips: 1ファイル 100MB〜1GB 程度を目安にすると、Snowflakeのプルーニングが効きやすい
④ Avro:スキーマ進化に強い行指向バイナリ
Kafkaなどストリーミング基盤で人気の形式。スキーマ情報をファイル内に持つ ので、後からカラムが増えても壊れにくいのが強みです。Snowflakeでは半構造化データとしてVARIANT 列に取り込めます。
- 向いている: ストリーミングパイプライン / スキーマが頻繁に変わるデータ
- 向いていない: 列単位のスキャンが中心の分析ワークロード
⑤ ORC:Hadoopエコシステム由来の列指向
Hiveから生まれた列指向フォーマットで、Parquetと並んで 圧縮効率と読み取り性能が高い のが特徴。既存のHive/Hadoop資産を持っている環境からSnowflakeへ移行する際に重宝します。- 向いている: 既存のHadoopクラスタからの移行 / HiveやSparkとの相互運用
- 向いていない: ゼロから新規にデータレイクを設計する場合(=Parquetが第一候補)

⑥ XML:レガシー連携の定番
DTDやXSDでスキーマを定義できる伝統的なフォーマット。金融や行政のシステム連携で今も現役です。SnowflakeではVARIANT 列に格納して扱えますが、サイズが大きくなりがちなので分析用というよりは取り込み入口として使うのが一般的です。
- 向いている: レガシーシステムからの取り込み / 業界標準フォーマットへの対応
- 向いていない: 大規模な分析ワークロード(取り込んだあとParquetに変換するのが定石)
どれを選ぶ?ユースケース別の早見表
迷ったら下記のフローチャート的な指針を参考にしてください。| こんなケース | 推奨形式 | 理由 |
|---|---|---|
| 数MB〜数百MBの手動エクスポート | CSV | どこでも開けて取り回しが楽 |
| APIや業務システムのレスポンスをそのまま蓄積 | JSON | ネスト構造のまま VARIANT に格納 |
| 数十GB以上の分析データ / 外部テーブル | Parquet | 列指向 + 圧縮効率 + プルーニング効率が最強クラス |
| Kafkaなどストリーミングからの連携 | Avro | スキーマ進化に強く、1行追記との相性◎ |
| 既存のHadoop/Hive資産を活用 | ORC | Hiveとの互換性が高い |
| 金融や行政の業界標準ファイル | XML | スキーマ定義つきで標準準拠 |
FILE FORMATオブジェクトを作ってみよう
Snowflakeでは、形式ごとの設定を FILE FORMATオブジェクト として保存しておけます。COPY INTOでデータ投入 するときに使い回せるので便利です。-- CSV用
CREATE OR REPLACE FILE FORMAT my_csv_format
TYPE = CSV
FIELD_DELIMITER = ','
SKIP_HEADER = 1
NULL_IF = ('NULL', '')
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
ENCODING = 'UTF8';
-- JSON用
CREATE OR REPLACE FILE FORMAT my_json_format
TYPE = JSON
STRIP_OUTER_ARRAY = TRUE;
-- Parquet用
CREATE OR REPLACE FILE FORMAT my_parquet_format
TYPE = PARQUET;
-- Avro用
CREATE OR REPLACE FILE FORMAT my_avro_format
TYPE = AVRO;
-- ORC用
CREATE OR REPLACE FILE FORMAT my_orc_format
TYPE = ORC;
-- XML用
CREATE OR REPLACE FILE FORMAT my_xml_format
TYPE = XML
STRIP_OUTER_ELEMENT = TRUE;COPY INTOで実際にロードしてみる
作成したFILE FORMAT は、COPY INTO 文の FILE_FORMAT オプションで参照できます。
-- CSVをテーブルに取り込む
COPY INTO my_table
FROM @my_stage/sample.csv
FILE_FORMAT = (FORMAT_NAME = my_csv_format)
ON_ERROR = 'CONTINUE';
-- ParquetをVARIANTカラムに取り込む(半構造化のまま)
COPY INTO raw_events (data)
FROM @my_stage/events.parquet
FILE_FORMAT = (FORMAT_NAME = my_parquet_format);よくある質問(FAQ)
Q. CSVとParquetはどちらでロードした方が速いですか?
データ量がある程度大きい場合(目安として数GB以上)は 圧倒的にParquet が速く、ストレージコストも安くなります。CSVは人が中身を確認したいときや小規模データ向けと割り切るのがおすすめです。Q. JSONを取り込むとき、ネスト構造はどう扱われますか?
VARIANT 列にそのまま格納され、data:user.name のようなドット記法やコロン記法でネスト要素にアクセスできます。フラット化したい場合は FLATTEN 関数や LATERAL 構文を組み合わせます。
Q. ParquetとORC、新規プロジェクトならどちらを選ぶべきですか?
新規であれば Parquet がおすすめです。ツール対応(Spark / Athena / BigQuery / Snowflake)が広く、コミュニティの情報も豊富です。ORCはHive/Hadoop資産を持っている場合に強みが出ます。Q. 半構造化データの圧縮はSnowflakeが自動でやってくれますか?
はい、Snowflakeはステージにロード後、自動で内部圧縮(マイクロパーティション + カラムナ格納)を行います。ただし ロード前のステージファイル自体の圧縮(gzip/snappy等) も別途設定可能で、転送コストと処理速度に影響します。Q. 1ファイルあたりの推奨サイズはありますか?
公式の推奨は 圧縮後で100〜250MB 程度です。小さすぎるとオーバーヘッドが増え、大きすぎると並列処理の恩恵を受けにくくなります。まとめ
ファイル形式選びは、ただの好みではなく ロード速度・ストレージコスト・分析性能 に直結する設計判断です。本記事のポイントをおさらいすると次のとおりです。- CSVは万能だがサイズと型情報に弱い → 小規模向け
- JSONはネスト構造をそのまま扱える → API/ログ向け
- Parquetは列指向で分析の事実上の標準 → 大規模分析の第一候補
- Avroはスキーマ進化に強い → ストリーミング向け
- ORCはHive資産との互換性が高い → 既存環境からの移行向け
- XMLはレガシー連携用 → そのまま分析するのは非推奨
参考リンク
取り込んだテキストデータをそのまま生成AIで処理したい場合は Snowflake Cortex LLM関数の使い方 も合わせてご覧ください。
関連記事
- Snowflakeデータロードの全体像|バルク・ストリーミング・サードパーティをやさしく解説 – データ取り込み手段の全体像をつかめます
- Snowflake COPY INTOでファイルからテーブルへデータ投入する方法 – FILE FORMATを実際に使うシーンの解説
- Snowflakeステージとは?内部・外部ステージをやさしく解説 – ファイルを置く場所「ステージ」の基本
- Snowpipeで自動取り込み!ファイルアップロードを検知する方法 – 継続的なファイル取り込みを自動化したい方へ

